
Un articlerepris su blog "HTTP BI, le blog des BU sur les publications électroniques et les données de la recherche" un site sous liecence CC by
La gestion des données (data management) désigne au sens large l’ensemble des activités facilitant :
- l’exploitation des données pendant un projet (stockage, partage entre partenaires, sécurisation, description, contrôle qualité…),
- leur préservation à plus ou moins long terme à l’issue du projet,
- leur réutilisation par les partenaires du projet ou éventuellement par des tiers.
La diffusion des données peut se faire quant à elle :
- à la demande (on parlera plutôt de « partage » dans ce cas) ou de bien de manière systématique,
- à destination d’un public large ou restreint
- et être assortie ou non de conditions ou de restrictions.
Il est en théorie envisageable de bien gérer des données sans pour autant les partager avec des tiers. Par contre, l’inverse n’est pas vrai : pour pouvoir diffuser des données, encore faut-il les avoir au préalable conservées, décrites et documentées. Les financeurs de la recherche, dont l’objectif est de favoriser le partage des données, préconisent donc également l’adoption de bonnes pratiques concernant leur gestion.
Un impératif : préserver, protéger et documenter ses données
Quel que soit l’ampleur du travail, du mémoire de master à la collaboration internationale impliquant des centaines de chercheurs, une perte ou une altération des données peut avoir des conséquences dramatiques pour le projet.
Un accès non autorisé aux données peut également être dangereux pour le projet, mais aussi pour des tierces personnes, en particulier s’il s’agit de données confidentielles ou personnelles. La collecte et le traitement des données personnelles obéit à une réglementation spécifique, appelée à évoluer en 2018, qu’a présentée le correspondant informatique et liberté de l’UNS lors d’une journée d’étude le 23 juin dernier.
Plus généralement, le guide « Pratiquer une recherche intègre et responsable » du comité d’éthique du CNRS (2e édition de décembre 2016) fait de la fiabilité et de la traçabilité des données produites et des traitements réalisés une bonne pratique nécessaire à la fiabilité du travail de recherche. Cela passe en sciences dures par la tenue d’un cahier de laboratoire, qui permet de faciliter le repérage des fraudes, de répondre aux demandes de vérification des relecteurs d’un article, et de sécuriser juridiquement la recherche en fournissant une preuve d’antériorité des résultats.
Partager ses données, quel intérêt pour le chercheur et pour la société ?
Au-delà d’une bonne gestion des données, dont l’intérêt est assez évident, quels sont les enjeux spécifiques du partage des données ?
Consolider la science
Une première série d’arguments sont d’ordre scientifique : améliorer la qualité de la recherche, sa visibilité et son impact, et faciliter de nouvelles recherches. Ils sont à replacer dans une logique générale de « science ouvertehttps://en.wikipedia.org/wiki/Open_science » : diffusion libre des articles, des données, du code informatique, des algorithmes, des protocoles, transparence de l’évaluation des résultats par les pairs, implication du public dans certaines recherches.
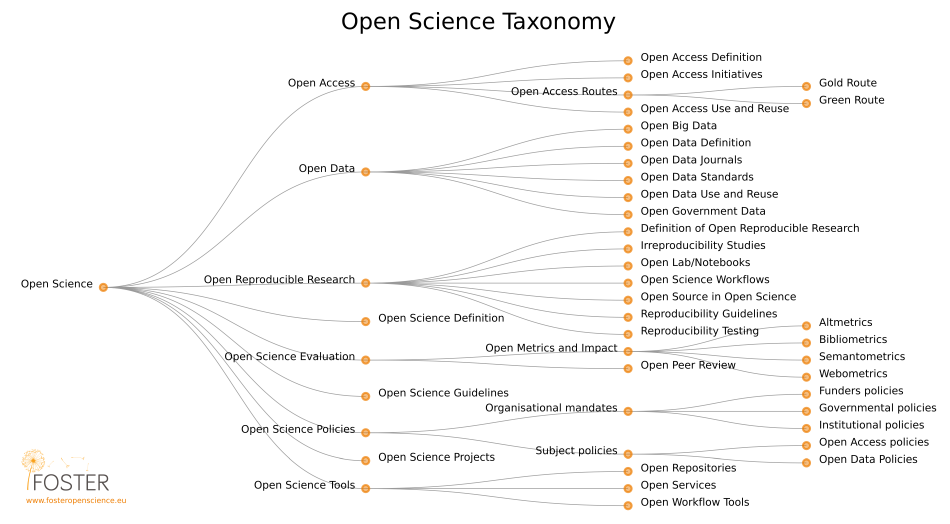
Différents volets de la science ouverte d’après le projet FOSTER
Revenons rapidement sur ces différents points :
Améliorer la qualité et la transparence de la recherche passe par une meilleure reproductibilité des expériences et des analyses. C’est un sujet brûlant en psychologie, en biologie et dans bien d’autres disciplines (voir ce manifesteparu il y a quelques jours dans une revue du groupe Nature). On distingue la « réplication » complète d’une étude, de la collecte des données au résultat final, souvent impossible, et la « reproduction » des résultats à partir des données brutes.
La diffusion des données renforce la visibilité et l’impact d’une étude. Statistiquement, les articles accompagnés de données sont plus cités que les autres (sélection d’articles sur le sujet).
Enfin elle permet de faire avancer plus vite la science :
- Constitution de bases de données internationales de référence, comme en génétique, ou en cristallographie.
- Méta-analyse synthétisant des données issues de plusieurs études pour consolider les connaissances sur un sujet.
- Agrégation ou comparaison de données liées à des lieux ou à des périodes
- Application de nouvelles méthodes ou de nouveaux outils à des données anciennes.
- Exploitation de sous-ensembles de données non analysés par leurs producteur (cas de plus en plus fréquent lié à l’augmentation de la taille des jeux de données).
- Nouvelles collaborations avec d’autres chercheurs.
La réutilisation de données est déjà bien établie en génétique ou en astronomie, mais encore balbutiante dans d’autres disciplines. En sciences sociales, elle est par exemple une pratique courante au Royaume-Uni, mais nettement plus marginale en France.
Renforcer la place de la science dans la société
D’autres arguments sont d’ordre socio-économiques, politiques ou patrimoniaux :
- Rationalité économique : la collecte et le traitement des données peuvent couter très cher, il faut donc les « rentabiliser » au maximum, et éviter de recréer des données déjà disponibles.
- Bon usage de l’argent public : la recherche financée sur fonds publics devrait bénéficier à tous, et donc être diffusée sans barrière et le plus largement possible.
- Utilité pour la société et les entreprises : cela concerne au premier chef les données d’essais cliniques, épidémiologiques, économiques, climatologiques, environnementales, etc. A titre d’exemple, la communauté scientifique américaine est fortement mobilisée depuis plusieurs mois pour préserver les données climatologiques, de peur que le président Trump ne les fasse disparaître ou ne restreigne leur disponibilité.
- Maîtrise des données par la communauté scientifique : même si des acteurs privés (éditeurs, sociétés spécialisées) ont un rôle à jouer dans la diffusion des données, la communauté scientifique doit pouvoir en conserver la maîtrise.
- Constitution d’un patrimoine scientifique. On peut aujourd’hui accéder aux oeuvres et aux travaux préparatoires de Darwin, Newton ou Claude Bernard. Mais de quels éléments disposeront nos héritiers pour documenter l’histoire de la science du XXIe siècle ?
- Respect des obligations et recommandations des universités, financeurs et revues. Ces politiques, variables selon les pays et les disciplines, ont été mises en place depuis une dizaine d’années pour apporter une réponse institutionnelle à tous les enjeux exposés précédemment.
Des freins et des difficultés à prendre au sérieux
Le partage et la réutilisation des données de la recherche sont encore loin d’être généralisés. Cela s’explique par différentes objections, qui sont de différents ordres.
Les objections pratiques sont multiples :
- Manque de temps.
- Coût lié à la préservation des données.
- Manque de compétences.
- Manque d’infrastructures adaptés.
L’organisation traditionnelle de la recherche et de la communication scientifique ne favorise pas le partage :
- Faible incitation institutionnelle.
- La communication des résultats scientifique passe avant tout par la rédaction d’articles.
- Manque de reconnaissance du partage de données dans le processus d’évaluation des chercheurs.
Un partage trop rapide et non préparé peut avoir des effets négatifs :
- Risque de mauvaise interprétation des données, qui pourrait nuire à leur producteur.
- Risque d’une mise en évidence d’erreurs dans la collecte ou le traitement des données.
- Risque de favoriser le travail d’une autre équipe au détriment de la sienne, dans un contexte de concurrence de plus en plus vive entre chercheurs. C’est particulièrement vrai lorsqu’un même jeu de données peut donner lieu à plusieurs publications étalées sur plusieurs années.
Les réticences les plus profondes sont liées à la nature même des processus de recherche :
- Difficultés théoriques ou méthodologiques pour réutiliser des données dans certaines disciplines : comme l’explique le projet ANR Reanalyse, « la démarche qualitative construit des données (observations, entretiens en particulier) qui sont produites dans l’interaction du chercheur avec le milieu qu’il étudie : leur -* Pratiques parfois trop hétérogènes pour que les données puissent facilement être réutilisées : manque d’un format commun partagé par tous les chercheurs une discipline, etc.
Enfin des questions juridiques et éthiques sont à prendre en considération :
- Utilisation de données personnelles ou sensibles, en particulier dans le domaine médical.
- Utilisation de données détenues par un tiers.
- En sciences sociales, la recherche « procède le plus souvent sur la base d’un contrat de confiance entre l’enquêté et l’enquêteur qui n’inclut pas la mise à disposition des informations fournies à d’autres que ceux à qui elles ont été confiées » (citation du projet Reanalyse)
Comment répondre à ces enjeux tout en tenant compte de ces freins ? Vous le saurez dans le prochain épisode !
En attendant, quelques liens pour aller plus loin si le sujet vous intéresse :
Pour s’informer
- Site national de veille et information sur les données de la recherche(MENESR, CNRS, INIST-CNRS, INSERM, INRA, IRD)
- Guide d’introduction aux données de la recherche destiné aux doctorants de Bretagne et Pays de Loire (site Formadoct)
- Services et ressources de l’INRA (peut être utile à des chercheurs non rattachés à l’INRA)
- Dossier du CIRAD(idem)
- Série d’articles sur le site des correspondants information scientifique et technique de l’Institut des SHS du CNRS
- Bon article de vulgarisation dans le journal du CNRS : « Préserver les données de la recherche à l’ère du Big Data« , 09/09/2016, par Guillaume Garvanèse
- Billet de l’URFIST de Paris : « Données » de la recherche, les mal-nommées, 15/11/2013 par Sylvie Fayet
Pour se former
- Projet Doranumde formation à distance sur la gestion et le partage des données (INIST-CNRS et réseau des URFIST, avec la participation de la BU de Nice)
- Services et tutoriels sur les données de la recherche sur produits par l’INIST-CNRS
Répondre à cet article
Suivre les commentaires : |
|
