
Comment fonctionne ChatGPT ? Décrypter son nom pour comprendre les modèles de langage
On voit passer beaucoup d’avis sur ChatGPT, mais finalement, qu’en sait-on ? Juste que c’est un réseau de neurones artificiels avec des milliards de paramètres, capable de tenir une discussion de haut niveau, mais aussi de tomber dans des pièges grossiers tendus par des internautes facétieux. On nous parle beaucoup de lui mais on en sait finalement très peu sur son fonctionnement.
Je vous propose donc de présenter les mécanismes principaux sur lesquels ChatGPT repose et de montrer ainsi que, si le résultat est parfois impressionnant, ses mécanismes élémentaires sont astucieux mais pas vraiment nouveaux. Pour ce faire, passons en revue les différents termes du sigle « ChatGPT ».
T comme transformer
Un « transformer » est un réseau de neurones qui bénéficie du même algorithme d’apprentissage que les réseaux profonds (deep networks), qui a déjà fait ses preuves pour l’entraînement de grosses architectures. Il bénéficie également de deux caractéristiques éprouvées : d’une part, des techniques de « plongement lexical » pour coder les mots ; d’autre part, des techniques attentionnelles pour prendre en compte le fait que les mots sont séquentiels.
Ce second point est majeur pour interpréter le sens de chaque mot dans le contexte de la phrase entière. La technique proposée par les transformers privilégie une approche numérique et statistique, simple à calculer massivement et très efficace. Cette approche consiste à apprendre, pour chaque mot et à partir de l’observation de nombreux textes, à quels autres mots de la phrase il faut faire « attention » pour identifier le contexte qui peut modifier le sens de ce mot. Ceci permet d’accorder un mot ou de remplacer un pronom par les mots de la phrase qu’il représente.
G comme génératif
ChatGPT est capable de générer du langage : on lui expose un problème et il nous répond avec du langage – c’est un « modèle de langage ».
La possibilité d’apprendre un modèle génératif avec un réseau de neurones date de plus de trente ans : dans un modèle d’auto-encodeur, la sortie du réseau est entraînée pour reproduire le plus fidèlement possible son entrée (par exemple une image de visage), en passant par une couche de neurones intermédiaire, choisie de petite taille : si on peut reproduire l’entrée en passant par une représentation aussi compacte, c’est que les aspects les plus importants de cette entrée (le nez, les yeux) sont conservés dans le codage de cette couche intermédiaire (mais les détails doivent être négligés car il y a moins de place pour représenter l’information). Ils sont ensuite décodés pour reconstruire un visage similaire en sortie.
Utilisé en mode génératif, on choisit une activité au hasard pour la couche intermédiaire et on obtient en sortie, à travers le décodeur, quelque chose qui ressemblera à un visage avec un nez et des yeux mais qui sera un exemplaire inédit du phénomène considéré.
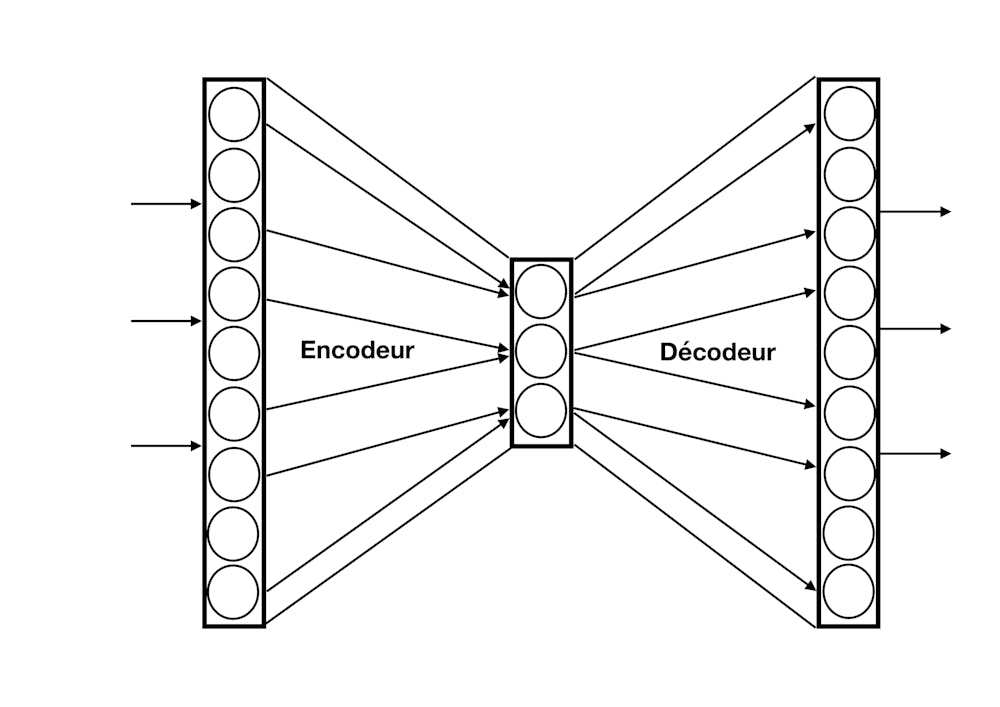
C’est par exemple en suivant ce procédé (avec des réseaux de grande taille) que l’on est capable de créer des deepfakes, c’est-à-dire des trucages très réalistes.
Si on souhaite maintenant générer des phénomènes séquentiels (des vidéos ou des phrases), il faut prendre en compte l’aspect séquentiel du flux d’entrée. Ceci peut être obtenu avec le mécanisme attentionnel décrit plus haut, utilisé sous une forme prédictive. En pratique, si l’on masque un mot ou si on cherche le mot suivant, on peut prédire ce mot manquant à partir de l’analyse statistique des autres textes. À titre d’illustration, voyez à quel point vous êtes capables de lire une BD des Schtroumpfs et de remplacer chaque « schtroumpf » par un mot issu de l’analyse attentionnelle des autres mots.
L’efficacité d’un simple mécanisme attentionnel (qui considère les autres mots importants du contexte mais pas explicitement leur ordre) pour traiter l’aspect séquentiel des entrées a été un constat majeur dans la mise au point des transformers (« Vous n’avez besoin que d’attention » titrait la publication correspondante : « Attention is all you need »), car auparavant les méthodes privilégiées utilisaient des réseaux plus complexes, dits récurrents, dont l’apprentissage est comparativement bien plus lent et moins efficace ; de plus ce mécanisme attentionnel se parallélise très bien, ce qui accélère d’autant plus cette approche.
P comme pretrained
L’efficacité des transformers n’est pas seulement due à la puissance de ces méthodes, mais aussi (et surtout) à la taille des réseaux et des connaissances qu’ils ingurgitent pour s’entrainer.
Les détails chiffrés sont difficiles à obtenir, mais on entend parler pour des transformers de milliards de paramètres (de poids dans les réseaux de neurones) ; pour être plus efficaces, plusieurs mécanismes attentionnels (jusqu’à cent) sont construits en parallèle pour mieux explorer les possibles (on parle d’attention « multi-tête »), on peut avoir une succession d’une dizaine d’encodeurs et de décodeurs, etc.
Rappelons que l’algorithme d’apprentissage des deep networks est générique et s’applique quelle que soit la profondeur (et la largeur) des réseaux ; il suffit juste d’avoir assez d’exemples pour entraîner tous ces poids, ce qui renvoie à une autre caractéristique démesurée de ces réseaux : la quantité de données utilisée dans la phase d’apprentissage.
Ici aussi, peu d’informations officielles, mais il semble que des pans entiers d’internet soient aspirés pour participer à l’entrainement de ces modèles de langages, en particulier l’ensemble de Wikipedia, les quelques millions de livres que l’on trouve sur Internet (dont des versions traduites par des humains sont très utiles pour préparer des transformers de traduction), mais aussi très probablement les textes que l’on peut trouver sur nos réseaux sociaux favoris.
Cet entrainement massif se déroule hors ligne, peut durer des semaines et utiliser des ressources calculatoires et énergétiques démesurées (chiffrées à plusieurs millions de dollars, sans parler des aspects environnementaux d’émission de CO₂, associés à ces calculs).
Chat comme bavarder
Nous sommes maintenant en meilleure position pour présenter ChatGPT : il s’agit d’un agent conversationnel, bâti sur un modèle de langage qui est un transformer génératif pré-entraîné (GPT).
Les analyses statistiques (avec approches attentionnelles) des très grands corpus utilisés permettent de créer des séquences de mots ayant une syntaxe de très bonne qualité. Les techniques de plongement lexical offrent des propriétés de proximité sémantique qui donnent des phrases dont le sens est souvent satisfaisant.
Outre cette capacité à savoir générer du langage de bonne qualité, un agent conversationnel doit aussi savoir converser, c’est-à-dire analyser les questions qu’on lui pose et y apporter des réponses pertinentes (ou détecter les pièges pour les éviter). C’est ce qui a été entrepris par une autre phase d’apprentissage hors-ligne, avec un modèle appelé « InstructGPT », qui a nécessité la participation d’humains qui jouaient à faire l’agent conversationnel ou à pointer des sujets à éviter. Il s’agit dans ce cas d’un « apprentissage par renforcement » : celui-ci permet de sélectionner des réponses selon les valeurs qu’on leur donne ; c’est une sorte de semi-supervision où les humains disent ce qu’ils auraient aimé entendre (ou pas).
ChatGPT fait ce pour quoi il a été programmé
Les caractéristiques énoncées ici permettent de comprendre que la principale fonction de ChatGPT est de prédire le mot suivant le plus probable à partir des nombreux textes qu’il a déjà vus et, parmi les différentes suites probables, de sélectionner celles qu’en général les humains préfèrent.
Cette suite de traitements peut comporter des approximations, quand on évalue des statistiques ou dans les phases de décodage du modèle génératif quand on construit de nouveaux exemples.
Ceci explique aussi des phénomènes d’hallucinations rapportées, quand on lui demande la biographie de quelqu’un ou des détails sur une entreprise et qu’il invente des chiffres et des faits. Ce qu’on lui a appris à faire c’est de construire des phrases plausibles et cohérentes, pas des phrases véridiques. Ce n’est pas la peine de comprendre un sujet pour savoir en parler avec éloquence, sans donner forcément de garantie sur la qualité de ses réponses (mais des humains aussi savent faire ça…).![]() http://theconversation.com/republishing-guidelines —>
http://theconversation.com/republishing-guidelines —>
Frédéric Alexandre, Directeur de recherche en neurosciences computationnelles, Université de Bordeaux, Inria
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
Répondre à cet article
Suivre les commentaires : |
|
