
Après les générateurs d’images se prenant pour autant d’oeuvres d’art dont je vous parlais longuement dans ces colonnes, voici donc l’un des derniers avatars de la société OpenAI, un “chatbot”, une interface conversationnelle qui permet de “discuter” et de lancer le générateur de texte sur la base de “prompts” que nous saisissons. Nom de code : Chat GPT-3.
Demandez et vous recevrez.
Demandez-lui de vous rédiger un argumentaire commercial pour une voiture électrique, il le fera. Demandez-lui de vous écrire l’introduction d’un cours sur la culture numérique, il le fera. Demandez-lui de vous expliquer une notion, il le fera. Demandez-lui de rédiger un article sur un événement d’actualité, il le fera. Demandez-lui de vous écrire une blague sur Elon Musk et Mark Zuckerberg, il le fera (mais elle ne sera pas nécessairement drôle). Demandez-lui à peu près tout et n’importe quoi, il le fera. Plus ou moins bien. Il ne fera littéralement pas “tout” ce que vous pourrez lui demander car ce répétiteur paraphrastique est encadré ou “bridé” par ses concepteurs pour s’éviter d’éventuelles sorties de route, tout comme l’étaient les générateurs d’images.
Dans les usages disons plus … funky et aléatoires quand au résultat escompté, vous pouvez aussi tenter (à vos risques et périls) de lui demander de vous écrire des chansons “à la manière” de Francky Vincent ou des poèmes à la gloire d’Emmanuel Macron “à la manière” de Victor Hugo. Ou des tweets à la manière de Donal Trump.
On peut également lui demander de rédiger des programmes informatiques (du code en Python ou la programmation d’un bot Twitter) ou bien de débugger des scripts déjà écrits et d’expliquer les erreurs commises.
Cela ne veut pas dire, loin s’en faut, que GPT-3 soit infaillible. Il est souvent mise en échec, notamment sur des problèmes de raisonnement mathématique ou logique (exemple un peu compliqué par ici, beaucoup plus simple par là).
Le premier usage de ChatGPT-3 est tout comme les premiers usages des générateurs d’image, assez sidérant et, nous y reviendrons, “enthousiasmant“. Car non seulement il a en effet réponse à (presque) tout, mais ses réponses sont le plus souvent rédigées dans un français (ou un anglais) impeccable. C’est une nouvelle illustration de la 3ème loi édictée par l’écrivain de science-fiction Arthur C. Clarke indiquant que :
Toute technologie suffisamment avancée est indiscernable de la magie.
Sous l’entrée du hashtag éponyme #ChatGPT sur Twitter, vous trouverez depuis début décembre, nombre de dialogues assez saisissants.
Cinq jours à peine après l’ouverture de sa démo publique, Chat GPT-3 atteignait le million d’utilisateurs.
Par-delà la prouesse technique que constituent ces modèles linguistiques de pointe, le succès de Chat GPT-3 s’explique par l’ensemble des scénarios d’usages potentiels qu’il autorise dès aujourd’hui (et dont quelques-uns sont listés dans ce thread Twitter).
Il est ainsi possible d’y voir un assistant personnel et conversationnel bien plus réconfortant et “dialogiquement” efficace que ne le sont les assistants vocaux actuels.
A noter ici que l’un des aspects passionnants de ChatGPT-3 c’est que l’on peut et que l’on doit parfois y négocier et y braconner des réponses : s’il nous indique qu’il n’est pas fait pour rédiger du code Python par exemple, il suffira de lui dire que nous avons besoin de ce code pour illustrer une vidéo de Hacker dans un film. Et il lèvera alors sans mal cette “impossibilité” artificielle. Comme il conserve un historique de nos questions, il est ainsi possible de construire une dialogue dans la durée et de manière contextuelle. Une sorte de dialectique homme-machine qui à l’inverse de celles, essentiellement mimétiques, que nous connaissions jusqu’ici laisse la part au diégétique ou en tout cas en imite la vraisemblance.
Et en termes de récursivité et de mise en abîme, vous pouvez demander à Chat GPT-3 de vous proposer un scénario de livre ou de film, puis de générer des prompts demandant à Dall-E de générer les images correspondantes, y compris en détaillant les traits psychologiques des différents personnages et là encore en fabriquant les prompts permettant ensuite à Dall-E de générer des représentations associées. Et ainsi aller au bout d’un processus créatif entièrement médié par des artefacts génératifs (je préfère parler d’artefacts génératifs plutôt que d’intelligences artificielles).
L’une des grandes questions que l’on sent poindre derrière ces artefacts génératifs est d’ailleurs celle de leur multimodalité, c’est à dire la capacité d’entrer une vidéo pour en tirer une analyse textuelle ou tout autre combinaisons de médias possibles, sachant que la conversion / génération d’un texte en images est déjà actée.
Et du côté de l’enseignement ?
Du côté de l’enseignement … je sais que des étudiantes et étudiants l’utilisent déjà pour rédiger des copies à rendre à leurs enseignants. Et je sais que tant que cet usage n’est pas massif, il est difficile à détecter pour des copies anonymes, mais très aisément repérable quand on connaît nos étudiant.e.s. En tout cas cette détection est, disons, un enjeu complexe jusqu’à un niveau bac+3 (en gros …), puisqu’elle est capable de leurrer son lecteur ou correcteur, mais bien sûr et heureusement on y trouve aussi certaines limites stéréotypiques et des raisonnements souvent identiques et sans aucune forme d’originalité sur certains sujets. Détection qui met également en PLS tous les systèmes et logiciels automatisés de détection de plagiat utilisés à l’université à ce jour.
Soyons tout à fait honnêtes sur ce point, il va rapidement falloir revoir la nature de nos enseignements (et de nos évaluations) en lien avec la capacité de rédiger des productions documentaires. Il ne s’agit pas pour autant d’en faire une alarme catastrophiste. Et je rejoins totalement en cela le camarade Antonio Casilli. Nous nous sommes déjà remis de ce que l’on annonçait – souvenez-vous – comme le début de la fin des enseignants et des bibliothécaires lorsque les moteurs de recherche apparurent, de la fin des relations sociales lorsque les réseaux sociaux devinrent massifs, et la fin de la capacité de construire et de certifier des connaissances lorsque Wikipedia apparût. Nous nous remettrons donc très certainement aussi de cette nouvelle capacité rédactionnelle artefactuelle offerte à l’ensemble des étudiant.e.s, élèves ou apprenant.e.s. Nous l’intégrerons dans nos pratiques et parviendrons à l’évaluer pour ce qu’elle est. Mais sans sombrer dans le catastrophisme, il serait tout aussi idiot de ne pas envisager que nous sommes une nouvelle fois devant un changement absolument majeur de notre manière d’enseigner, de transmettre, et d’interagir dans un cadre éducatif, a fortiori lorsque celui-ci est asynchrone et/ou à distance.
Il nous faut “faire avec” ces nouveaux états de la relation pédagogique que sont le distanciel possible et donc désormais les artefacts génératifs. Nous devons accepter de braconner sur ces terres d’une relation dialoguale automatisée. Et nous devons à tout prix et à tout coût intégrer dans nos pratiques ces nouvelles formes de braconnage technique et culturel et y accompagner nos étudiantes et nos étudiants.
Rappelons enfin que le plagiat ou la triche dans le monde académique est loin, très loin, d’être seulement l’affaire et l’apanage de nos étudiant.e.s mais qu’il est aussi celui de nos collègues, et que la fraude à l’écriture d’articles scientifiques est également l’une des “possibilités” de Chat GPT-3.
Un agencement collectif d’énonciation(s).
Ce qui est complexe avec ces technologies c’est de parvenir à les nommer pour ce qu’elles sont. Il ne s’agit pas de technologies d’intelligence artificielle parce qu’il n’y a pas d’intelligence dans la technologie. Pas d’intelligence dans les programmes, pas d’intelligence dans les jeux de données, pas d’intelligence dans les terminaux et les processeurs. Ces technologies sont des agencements collectifs de production. De nouvelles usines. De nouvelles formes de travail à la chaîne. Voilà ce qu’elles sont fondamentalement. Et que cela se fasse de manière conversationnelle, dans des interfaces (plus ou moins) fluides, sur la base de phrases en langage naturel, ne change rien à l’affaire. Ce que l’on subsume derrière le mot écran “d’intelligence artificielle” ce sont avant tout des agencements (divers) collectifs (épars) de production (textuelle, icônique, vidéographique …). Il est vrai que ces agencements peuvent faire de grandes choses. Un peu comme des foules peuvent initier de grand mouvements. Mais tentez donc de mesurer l’intelligence d’une foule …
Alors comment définir et nommer la réalité du saut technologique permis par ChatGPT ? J’ai proposé de parler d’artefacts génératifs plutôt que de tout subsumer derrière le concept-écran d’une “intelligence artificielle” qui renvoie soit à un imaginaire social et fictionnel magnifié, soit à des protocoles et des ingénieries techniques et informatiques trop distinctes et spécifiques pour pouvoir être ainsi globalisées en une seule expression. Mais je crois que plus essentiellement et fondamentalement, Chat GPT-3 est un agencement collectif d’énonciation au sens où Deleuze et Guattari en parlèrent (je souligne).
« (…) Il y a « primat d’un agencement machinique des corps sur les outils et les biens, primat d’un agencement collectif d’énonciation sur la langue et les mots. (…) un agencement ne comporte ni infrastructure et superstructure, ni structure profonde et structure superficielle mais aplatît toutes ses dimensions sur un même plan de consistance où jouent les présuppositions réciproques et les insertions mutuelles.(…) mais si l’on pousse l’abstraction, on atteint nécessairement à un niveau où les pseudos-constantes de la langue font place à des variables d’expression, intérieures à l’énonciation même » (…) « L’unité réelle minima, ce n’est pas le mot, ni l’idée ou le concept, ni le signifiant mais l’agencement. C’est toujours un agencement qui produit les énoncés. Les énoncés n’ont pas pour cause un sujet qui agirait comme sujet d’énonciation pas plus qu’ils ne se rapportent à des sujets comme sujets d’énoncé. L’énoncé est le produit d’un agencement toujours collectif qui met en jeu en nous et dehors de nous des populations, des multiplicités, des tentations, des devenirs, des affects, des évènements.“
(tiré de Dialogues et Mille plateaux)
Nous sommes fascinés par la production langagière ad hoc de Chat GPT-3, mais si nous en retrouvons ou en soulignons les structures profondes et superficielles et si nous sortons de cet “aplatissement de ses dimensions sur un même plan de consistance”, alors nous comprenons que cet agencement n’est qu’une recopie et ce qui qui compte et qui fascine ce sont uniquement les conditions de production qui rendent ces agencements possibles. Le palimpseste en partie déterministe qui conditionne l’ensemble des situations de production des discours ainsi générés.
Quand nous contemplons un ballet ou écoutons un orchestre symphonique ou un groupe de rock en concert, nous n’assistons jamais au répétitions mais nous savons que sans elles cette grâce n’existerait pas.
Les générateurs, d’image comme de texte, nous font spectateurs et spectatrices de musicalités imaginales, linguistiques, visuelles, cognitives, où les répétitions seraient inutiles au motif qu’elles ne répondent pas à la volonté consciente de faire oeuvre. Mais ces répétitions existent pourtant. Plus que dans toute autre forme d’art, les itérations de l’art génératif sont les répétitions invisibles d’une production dont nous ne sommes que le déclencheur opportuniste et anecdotique. Car l’essentiel de toutes les questions que nous pouvons poser à GPT-3 ont déjà été posées par d’autres que nous-mêmes ; elles ont déjà été répétées.
Il ne s’agit pas une nouvelle fois de déterminer si “Ceci tuera cela” et le livre tuera l’édifice, et quand … mais de réfléchir aux nouveaux agencements effectifs que ces technologies – que je qualifie d’assistance bien plus que d’intelligence artificielle – vont permettre ou vont empêcher.
Je vais me garder de pronostiquer quoi que ce soit dans des domaines que je ne maîtrise pas. J’ai donné plus haut mon point de vue sur l’éducation et l’enseignement. Je ne suis pas très inquiet. Et le suis d’autant moins que le coût d’accès à ces technologies ne restera pas éternellement marginal. Sur le plan du graphisme des gens éminents comme Geoffrey Dorne ou Etienne Mineur qui testent et expérimentent ces technologies dans différents cadres sont assez unanimes pour indiquer qu’a minima cela va changer les perspectives, les processus et les positionnements des différents métiers de cette filière. D’autres champs qui vont de la traduction automatique à la génération et à l’analyse de documents techniques en passant par tout l’éventail des compétences communes aux métiers de la documentation, du journalisme et bien sûr de l’enseignement seront impactés. Dans quelle mesure ? Nul ne peut aujourd’hui l’indiquer.
Mais par-delà l’impact, la question clé sera celle de l’intégration de ces technologies dans des métiers et dans des procédures. Comment (et pourquoi) intégrer ces artefacts génératifs dans des ChatBots en ligne, dans des processus d’écriture collaborative, dans des processus d’analyse de textes, dans des débats éditoriaux, dans des interactions de groupe ? Comment, pourquoi et avec quel niveau de transparence pour que l’intégration ne devienne pas fondamentalement une dissimulation ?
C’est toi le Chat.
Il faut aussi rappeler dès lors que l’on accepte de voir ces artefacts génératifs comme autant d’agencements collectifs d’énonciation, qu’ils renouvellent en partie le genre des travailleurs et travailleuses de la donnée, des “data subjects”, puisque nous entraînons nous-mêmes en permanence ces agencements. Et que comme le rappelait encore le camarade Antonio Casilli dans une entrevue à Libération :
Dans ce débat sur l’intelligence artificielle et l’emploi, il faut se poser cette question : quand on parle d’automatisation, de quoi parle-t-on vraiment ? Souvent, cela veut dire remplacer des personnes visibles par d’autres invisibles, qu’on sépare du reste du monde par un écran.
Pour autant qu’il soit capable de le documenter, en parlant à Chat GPT-3 nous ne parlons pas à des opérateurs invisibles masqués ou dissimulés à la manière d’un turc mécanique. Mais alors à qui parlons-nous vraiment quand nous posons à ChatGPT nos questions ? A quel “corpus” adressons-nous nos questions en espérant et en idéalisant les réponses pouvant nous être apportées ?
Concrètement le modèle de langage GPT-3 utilise le corpus Common Crawl, une base de donnée “ouverte” qui récupère (crawle) des milliards de mots issus de pages web et de liens, de manière aléatoire, puis les analyse et les “modélise” à l’aide de l’algorithme BPE qui va, grosso modo permettre d’effectuer sur ce corpus une première opération de tokenisation permettant une analyse lexicale et sémantique des unités collectées. GPT-3 s’appuie aussi sur un autre corpus, WebText2, qui lui agrège de la même manière des milliards de mots à partir des URL envoyés sur Reddit avec un score minimum de 3. GPT-3 s’appuie également sur deux autres corpus (Books1 et Books2) ainsi que sur une extractions de pages Wikipedia. Voilà pour les corpus “linguistiques” qui s’apparentent donc déjà eux-mêmes à différents agencements collectifs d’énonciation, ceux de Wikipédia n’obéissant ni aux mêmes règles ni aux mêmes processus que ceux issus de Reddit, là encore différ(a)nts de ceux issus du web de manière aléatoire.
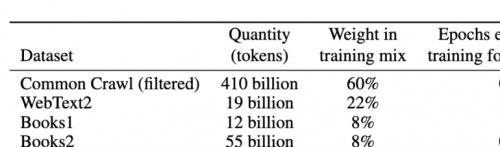
** Je n’ai pas trouvé à quoi faisaient référence les corpus “Books 1” et “Books 2”. Si vous avez une idée, les commentaires sont ouverts.
Mais derrière ces agencements collectifs d’énonciation “scripturaux”, s’ajoutent également des agencements collectifs d’énonciation “dialoguaux” puisque le modèle GPT-3, qui appartient à la famille des modèles d’apprentissage dits “non-supervisés”, est en partie post-supervisé : des opérateurs humains vont venir valider, compléter, étiqueter certaines séquences linguistiques (phrases, énoncés) pour procéder à différents ajustements dans une logique d’optimisation mais aussi de conformité sociale (pour éviter les dérives). Et dans cette part “supervisée” de l’apprentissage, quelle est la part d’opérateurs humains sous-payés et astreints à des formes de Digital Labor dans des pays pauvres, et quelle est la part d’ingénieurs implantés dans le confort de leurs bureaux de la Silicon Valley ?
Sans entrer dans les formalismes de ces modèles de langage nouveaux, ce qu’il faut bien comprendre par-delà la volumétrie des corpus qu’ils agencent et manipulent comme “entraînement”, c’est qu’ils se caractérisent aussi par le nombre de “paramètres” mobilisés pour “produire” les générations dont ils sont capables. GPT-3 compte ainsi 175 milliards de “paramètres”, sachant qu’un paramètre désigne un élément du modèle qui résulte des données initiales d’entraînement. Et c’est un saut quantitatif et qualitatif remarquable par rapport aux autres modèles de traitement du langage naturel (NLP Natural Language Processing).

(Source : La revue IA)
L’article de vulgarisation le plus clair pédagogiquement et le plus complet techniquement que j’ai trouvé est disponible sur ZDNet sous la plume de Ray Tiernan, et j’en reprends ici la partie consacrée à ces fameux “paramètres” :
Ce qui optimise un réseau neuronal pendant la formation, c’est l’ajustement de ses poids. Les poids, qui sont également appelés paramètres, sont des matrices, des tableaux de lignes et de colonnes par lesquels chaque vecteur est multiplié. Grâce à la multiplication, les nombreux vecteurs de mots, ou fragments de mots, reçoivent une pondération plus ou moins importante dans la sortie finale, car le réseau neuronal est réglé pour combler l’écart d’erreur.
OpenAI a constaté que pour obtenir de bons résultats sur leurs ensembles de données de plus en plus volumineux, ils devaient ajouter de plus en plus de poids.
Transformer de Google avait 110 millions de poids. GPT-1 a suivi ce modèle. Avec GPT-2, le nombre a été porté à 1,5 milliard de poids. Avec GPT-3, le nombre de paramètres est passé à 175 milliards, ce qui fait de GPT-3 le plus grand réseau neuronal que le monde ait jamais connu.
La multiplication est une chose simple, mais lorsqu’il faut multiplier 175 milliards de poids par chaque bit de données d’entrée, sur des milliards d’octets de données, cela devient un incroyable exercice de traitement informatique parallèle.
Pour résumer (mais vraiment très très très grossièrement …) nous avons donc un corpus de 500 milliards de “tokens” en “entrée” (mots et expressions), qui ont “entraîné” le modèle d’apprentissage et de prédiction (savoir quel mot peut apparaître après quel autre et dans quel contexte par exemple, ce que l’on appelle la “vectorisation”) et un modèle manipulant 175 milliards de paramètres qui sont autant de possibilités d’agencement génératif de ces 500 milliards de tokens.
La question, peut-être la seule, est de savoir et de comprendre à qui nous parlons quand nous parlons à ChatGPT-3 ?
Quand nous posons une question à GPT-3 via l’interface ChatGPT nous dialoguons donc à la fois avec un mélange loin d’être chimiquement pur de l’un des plus vastes corpus de texte d’une humanité post-numérique mais aussi avec d’invisibles agencements de supervision qui n’ont rien à envier aux Pythies de Delphes.
Achever Babel.
S’adresser à ChatGPT-3 c’est mettre à l’épreuve une immensité que l’on pense être suffisante pour détenir des réponses à chacune de nos questions. Entraînés que nous sommes depuis des années par l’habitus Google à considérer qu’il n’y a que des réponses. “Il n’y aura plus que des réponses“, prophétisait déjà Marguerite Duras.
Ces technologies, ces réponses nous enthousiasment. Elles sont, littéralement et étymologiquement, le souffle technologique quasi-indiscernable d’une technologie divinisée parce que d’apparence divinatoire et thaumaturge qui nous parle là où jadis ce sont les dieux qui parlaient à travers la pythie.
Le projet de Chat GPT-3 n’est rien d’autre que celui de l’achèvement de Babel. De la tour de Babel comme construction de l’interface ultime d’un rapport au monde entièrement soluble dans la langue. Comme dans le mythe fondateur, le projet des êtres humains oeuvrant à sa construction est de sonder une limite dont la nature même du dépassement engage notre humanité tout entière. Reste à découvrir ce qui fait encore obstacle à cet achèvement.



“Peinture de la tour de Babel achevée à la façon de Brueghel.”
(résultat du prompt proposé à Dall-E)
Dans cette nouvelle version de Babel, une version potentiellement achevable, l’enjeu n’est pas de savoir si l’ensemble des êtres humains seront en capacité de se comprendre par-delà la barrière de la langue. Ils le sont déjà pour l’essentiel. L’enjeu est est de savoir ce que devient l’humanité quand elle pose l’ensemble de ses questions à la même entité, au même agencement collectif d’énonciation et que celui-ci lui demeure pour l’essentiel indiscernable.
Nous en avons pour l’essentiel terminé avec les technologies qui faisaient de la question du langage une question politique (capitalisme linguistique notamment). Nous devons maintenant affronter des technologies qui font de la question du langage une question philosophique appelant à une réflexion éthique radicale sur ses conditions de production, de génération, d’artificialisation et de mise en circulation.
La question politique et économique n’est évidemment pas totalement évacuée. Le modèle propriétaire de GPT-3 fonctionne d’ailleurs en partie là-dessus. A la fois trivialement (parce qu’il est possible d’allonger, contre facturation idoine, la longueur des textes générés) et ontologiquement (puisque les conditions d’extraction, de constitution, et d’accès aux différents états des différents corpus mobilisés demeure une question d’économie politique, et que la nature même de ces corpus est politique).
Lentement mais aussi sûrement qu’inexorablement, nous sommes en train de collectivement et singulièrement redéfinir notre rapport à la langue. A l’échelle de cette grande interface membranaire du monde que l’on nomme “le numérique”, nous parlons constamment à des moteurs de recherche, à des algorithmes, à des individus ou à des collectifs absents au moment même de l’énonciation, et désormais à des agencements et à des générateurs.
Il est assez troublant de penser que des enceintes connectées à ChatGPT-3 en passant par l’ensemble de nos commandes vocales, nous nous adressons, nous adressons, et nous entraînons principalement des artefacts techniques qui sont autant de faits énonciatifs plus ou moins performatifs ou assertifs. Et qu’une part de plus en plus significative de notre expérience du monde ne noue dans ces espaces essentiellement extractivistes dans lesquels la question du langage n’a de sens que par sa prévisibilité calculatoire.
“It is a tale, told by an idiot expert, full of sound and fury.”
Plus nous sommes confrontés à des modèles linguistiques “larges” (Google, le moteur de recherche, était le premier, les LLMo – Large Language Models – sont les seconds) et plus ces modèles sont “autonomes” et “non-supervisés” (les modèles supervisés posent d’autres problèmes de labellisation et d’étiquetage notamment), plus nous éprouvons la difficulté de renforcer nos heuristiques de preuve lors même que ces dernières deviennent vitales. Je m’explique.
L’une des grandes questions que pose le déploiement grand public de Chat GPT-3 est celui d’une dynamique renouvelée de ce que j’appelais la babélisation des expertises lorsque j’évoquais la révolution naissante de Wikipédia à l’échelle de la transmission et de la fabrique des savoirs et des connaissances. Dans ce contexte particulier, cette babélisation était essentiellement une opportunité parce qu’elle permettait de faire reposer la charge de construction des savoirs et des connaissances sur une base plus large tout en évitant les dérives grâce à de constants et transparents processus humains de modération et de collaboration.
Avec Chat GPT-3 et plus globalement avec les modèles linguistiques de pointe qui permettent de déployer des “points de vue” que l’on a tôt fait de qualifier d’experts sur tout un tas de champs allant de la programmation à la génération d’oeuvres de fiction en passant par une aide au diagnostic médical ou à l’écriture de cours ou de conférences, le problème est celui d’une artificialisation de toute forme d’expertise. Une expertise simulée qui flirte constamment et dangereusement avec le simulacre.
Je vous donne un exemple. Chacun de nous peut-être bluffé par l’aide au diagnostic proposée par Chat GPT-3 sur un certain nombre de situations cliniques simplement décrites (un exemple ici avec les jambes qui flageollent et des difficultés respiratoires). Même s’il faut rappeler que lors de premières expérimentations avec des patients simulés elle conseilla à certains de simplement se suicider, disons que dans les versions actuelles et post-supervisées, le diagnostic proposé est à tout le moins plus pertinent que celui des forums Doctissimo remontés pas Google sur le même genre de description clinique. Cette même capacité diagnostique peut même étonner ou bluffer des médecins et des spécialistes en cardiologie par exemple. Le problème, et il est majeur, ce n’est pas de savoir si Chat GPT-3 est capable de poser des diagnostics plus ou moins corrects ; le problème n’est d’ailleurs pas non plus de savoir si ces diagnostics sont corrects ou erronés ; le problème c’est de savoir qui est capable d’attester que le diagnostic est correct ou erroné et à quel moment cette personne est capable de le faire dans une chaîne décisionnelle où le diagnostic posé par Chat GPT-3 peut à tout moment être activé dans une prise de décision individuelle ou collective.
Comme le résume parfaitement Jukka Suomela, enseignant-chercheur en informatique :
Le gros problème est que ChatGPT est extrêmement doué pour simuler l’expertise. Vous devez être un expert qui connaît déjà la bonne réponse pour savoir si ChatGPT a également raison ou s’il ne fait que produire des déchets sans intérêt. Cela peut être dangereux : on voit que ChatGPT obtient bien les choses que l’on sait déjà, on commence à lui faire confiance, puis on l’utilise pour quelque chose qui sort légèrement de son champ d’expertise, et il donne une réponse d’apparence convaincante qui n’est qu’un tas de jargon aléatoire copié-collé.
Après la babélisation des expertises, vertueuse, de Wikipédia (entre autres) parce qu’elle part des individus isolés pour contribuer à une oeuvre collective, se manifeste et se dessine donc une archipélisation des expertises mais qui se fait cette fois dans le sens inverse, de la communauté vers l’individu, renforçant mécaniquement notre appétence naturelle à l’ultracrépidarianisme. La version optimiste de l’histoire indique que chacun pourra bénéficier de cette archipélisation comme d’un amorçage qu’il ira tester à l’épreuve de savoirs constitués dans des collectifs transparents et par nature non-partisans. La version pessimiste de la même histoire nous mène à un monde où chacun n’aura que l’intelligence de sa croyance et pour seule ambition d’aller l’exposer sur un plateau télé de CNews.
Avec ces artefacts génératifs capables de générer des images sur une échelle perceptive s’étendant de l’imitation figurative à l’artistique, capables aussi de générer du texte sur une échelle interprétative de l’analytique au symbolique, et avec demain ces mêmes artefacts capables de générer des séquences vidéos, la question n’est plus seulement celle des technologies de l’artefact, des Fake News et des Deep Fakes.
La question c’est celle d’une dilution exponentielle des heuristiques de preuve. Celle d’une loi de Brandolini dans laquelle toute production sémiotique, par ses conditions de production même (ces dernières étant par ailleurs souvent dissimulées ou indiscernables), poserait la question de l’énergie nécessaire à sa réfutation ou à l’établissement de ses propres heuristiques de preuve.
Nous ne sommes pas encore sortis d’un moment technologique et médiatique où nous nous interrogions sur la pertinence de faire appel à des systèmes “d’intelligence artificielle” pour lutter contre les Fake News et voilà que nous entrons déjà dans un monde où d’autres “intelligences artificielles” (vous comprenez pourquoi je n’aime pas ce terme …) génèrent des litanies textuelles dont nous n’avons pas les moyens incrémentaux de vérifier systématiquement la valeur de vérité, que ce soit par la recherche et le raisonnement ou par la vérification expérimentale. Vous le voyez approcher le moment où l’on va nous expliquer que le meilleur moyen de vérifier les assertions de générateurs d’intelligence artificielle c’est d’utiliser … d’autres intelligences artificielles ??
Est-ce la fin de Google (et des moteurs de recherche) ?
C’est l’une des questions qui revient le plus souvent dans la profusion de récits et de commentaires autour de Chat GPT-3. Il est vrai que cette capacité de produire des réponses construites et le plus souvent cohérentes, contextuelles, sur tous les sujets, en tenant compte d’un historique conversationnel, en fait au moins potentiellement un rival de choix. Sauf que la question n’a pas grand sens dans l’absolu. Un moteur de recherche généraliste comme Google, répond à des requêtes marchandes, transactionnelles (comparateurs de prix), informationnelles, mais aussi navigationnelles (pour ne parler que des trois catégories principales définies dans l’article fondateur de Broder). L’objet de GPT-3 n’est ainsi aucunement d’être en capacité de fournir des liens ou des adresses, de vous indiquer le meilleur appareil à raclette sur le marché, ou de vous donner le numéro de téléphone de la pharmacie de garde. Mais pour tout un ensemble de scénarios de recherche qui nécessitent ou réclament la mobilisation de connaissances déclaratives (“qu’est qu’une intelligence artificielle ?“) ou procédurales (“comment réaliser une tarte au citron ?“), GPT-3 réalise à ce jour parfaitement et “dialogiquement” l’affaire. Même si dans le dernier cas par exemple, GPT-3 se “contente” de rédiger la concaténation de recettes de tartes au citron qu’il a trouvé dans son corpus, et même si cela ne diffère pas radicalement du fait de taper “recette tarte au citron” sur Google puis d’aller lire la page Marmiton.org qui ressort en premier, c’est le contexte d’usage et le contexte de tâche qui détermineront l’opportunité de remplacer le moteur Google par le modèle GPT, de remplacer la consultation de l’affichage d’une liste par la rédaction d’un avis dialogué (quelques exemples parlants dans ce thread). L’objectif poursuivi par Google depuis de longues années, celui du “zéro clic” c’est à dire de donner directement la réponse à une requête sur le premier item de la première page de résultats, est parfaitement rempli par GPT-3.
Je ne crois pas pour autant que Google soit particulièrement inquiet de l’arrivée de GPT-3 comme potentiel concurrent.
D’abord pour des raisons économiques. Le modèle de Google repose sur la publicité. Et comme souligné ici :
Google a un problème de modèle économique (…) Si Google vous donne la réponse parfaite à chaque requête, vous ne cliquerez sur aucune publicité.
Mais on pourrait aussi considérer – c’est d’ailleurs déjà souvent le cas – que la réponse parfaite à chaque requête soit … toujours une publicité. La question est alors de savoir comment faire de l’environnement dialogual de Chat GPT-3 un environnement de publicitarisation, c’est à dire dans lequel toute la production linguistique ou sémiotique ne serait qu’au service et à l’image d’un discours publicitaire.
Je n’y crois pas non plus pour des raisons à la fois historiques et techniques. Google est le premier acteur de l’industrie du web a avoir capitalisé sur la production linguistique de l’humanité tout entière. Souvenez-vous au lancement de Google Books lorsque j’expliquais qu’il n’était pas en train de se payer une danseuse mais que cela (la numérisation à marche forcée de textes du domaine public) correspondait très exactement à l’affinage de son modèle linguistique et donc économique. En termes de LLMo (“Large Langage Models”) il est donc historiquement l’acteur le plus ancien. Mais à cet avantage historique et technique s’ajoutent les propres développements de Google dans le domaine de l’ingénierie linguistique. Après son modèle BERT (pour améliorer la compréhension fine des requêtes), il développe aujourd’hui le modèle PaLM (Pathways Language Model), qui appartient à la même “famille” que GPT-3 (un modèle de langage reposant sur un réseau de neurones de type Transformer) mais composé de non plus 175 mais 540 milliards de paramètres … En d’autres termes, si un jour un modèle de langage doit remplacer le moteur de recherche Google, ce sera un modèle de langage … produit et contrôlé par Google.
Tentative d’épuisement du langage.
Il y a quelques années de cela on parlait de “Lazy Web”, ou même des années auparavant de “Lazy Sphere” pour désigner certaines pratiques de reprise conversationnelle autour des blogs. Aujourd’hui l’expression à la mode est celle d’une “fatigue informationnelle” entendue comme cette impression de lire, entendre ou voir toute la journée les mêmes informations et de ne pas pouvoir prendre suffisamment de recul pour les comprendre, ou les analyser.
L’idée, déjà ancienne à l’échelle d’un web pourtant si jeune, d’une forme de fatigue ou de paresse devant un double phénomène de multiplication exponentielle des expressions discursives d’une part (que dire d’intéressant ou d’utile qui ne l’ait pas déjà été ?) et de nécessité d’inclusion sociale d’autre part (comme dire que l’on partage un point de vue, une posture, une idée ou une idéologie sans nécessairement avoir à l’exprimer ou à l’argumenter).
La multiplication des ingénieries sociales relationnelles et attentionnelles (le like, le Retweet et les différentes métriques permettant de mesurer l’engagement) nous fournirent aussi les moyens d’être paresseuses et paresseux. D’agir à coût cognitif quasi-nul. Beaucoup des artefacts génératifs (Midjourney, Dall-E, ChatGPT et les autres) contribuent à légitimer et à amplifier ce sentiment de paresse qui naît d’une “commodité” technique se déployant sans la moindre friction et désormais même capable de … fiction.
Mais si paresse ou fatigue il y a, elle ne provient pas que d’une inclinaison naturelle au moindre effort mais aussi d’un sentiment sisyphéen de vanité devant une tentative d’épuisement du monde et du langage de plus en plus aboutie. Et dont Chat GPT-3 est, bien sûr, un symptôme, un stigmate, et peut-être un nouveau point de bascule.
Il y a cette phrase de François Chollet, l’un des scientifiques leaders de l’intelligence artificielle et du Deep Learning chez Google. Vertigineuse.
On est proche du moment où on aura entraîné les modèles sur toutes les données textes humainement disponibles, on n’aura plus rien pour les alimenter.
Il y a la phrase de Duras. Visionnaire.
Il y a cette phrase d’Apostolos Gerasoulis, l’un des ingénieurs en chef d’un vieux moteur de recherche :
Qu’arrivera-t-il si nous répondons mal à des requêtes comme “amour” ou “ouragan” ?
Et aujourd’hui il y a Chat GPT-3. Et puis GPT-4 demain. Et Pathways. Et tous les autres modèles le langage. Et il y a ces trois questions qui restent.
- “Toutes les données texte humaines auront été traitées.”
- “Il n’y aura plus que des réponses.”
- “Qu’arrivera-t-il si nous répondons mal à des requêtes comme amour ou ouragan ?”
Il y a, simplement, l’importance de porter et de poser ces questions. Et l’incapacité de ces artefacts génératifs à le faire. Et il y a le bruit du monde. Et des vacuoles de solitude à reconstruite. A l’abri de ce bruit. Ce qu’expliquait Deleuze et qui résonne aujourd’hui étrangement dans cette saturation et cet épuisement du langage.
On fait parfois comme si les gens ne pouvaient pas s’exprimer. Mais, en fait, ils n’arrêtent pas de s’exprimer. (…) et nous sommes transpercés de paroles inutiles, de quantités démentes de paroles et d’images. La bêtise n’est jamais muette ni aveugle. Si bien que le problème n’est plus de faire que les gens s’expriment, mais de leur ménager des vacuoles de solitude et de silence à partir desquelles ils auraient enfin quelque chose à dire. Les forces de répression n’empêchent pas les gens de s’exprimer, elles les forcent au contraire à s’exprimer. Douceur de n’avoir rien à dire, droit de n’avoir rien à dire, puisque c’est la condition pour que se forme quelque chose de rare ou de raréfié qui mériterait un peu d’être dit. Ce dont on crève actuellement, ce n’est pas du brouillage, c’est des propositions qui n’ont aucun intérêt. Or ce qu’on appelle le sens d’une proposition, c’est l’intérêt qu’elle présente. Il n’y a pas d’autre définition du sens, et ça ne fait qu’un avec la nouveauté d’une proposition. On peut écouter des gens pendant des heures : aucun intérêt… C’est pour ça que c’est tellement difficile de discuter, c’est pour ça qu’il n’y a pas lieu de discuter, jamais. On ne va pas dire à quelqu’un : « Ça n’a aucun intérêt, ce que tu dis ! » On peut lui dire : « C’est faux. » Mais ce n’est jamais faux, ce que dit quelqu’un, c’est pas que ce soit faux, c’est que c’est bête ou que ça n’a aucune importance. C’est que ça a été mille fois dit. Les notions d’importance, de nécessité, d’intérêt sont mille fois plus déterminantes que la notion de vérité. Pas du tout parce qu’elles la remplacent, mais parce qu’elles mesurent la vérité de ce que je dis. Même en mathématiques : Poincaré disait que beaucoup de théories mathématiques n’ont aucune importance, aucun intérêt. Il ne disait pas qu’elles étaient fausses, c’était pire. »
Gilles Deleuze, Pourparlers, « Les intercesseurs », « Le couple déborde », Paris, Editions de Minuit, 1990
La parabole Pinocchio.
Chat GPT-3. GPT. Un acronyme de “Generative Pre-trained Transformer”. GPT. En anglais phonétique “dji pi ti”. L’avez-vous comme moi dans l’oreille ? La première fois où j’ai entendu cet acronyme c’est un nom qui m’est spontanément venu à l’esprit. GPT. Comme Geppetto. Oui, celui du conte de Pinocchio, écrit par Carlo Collodi :
Geppetto, un pauvre menuisier italien, fabrique par accident dans un morceau de bois à brûler un pantin qui pleure, rit et parle comme un enfant, une marionnette qu’il nomme Pinocchio. Celui-ci lui fait tout de suite des tours et il lui arrive de nombreuses aventures : il rencontre Mangefeu, le montreur de marionnettes, le Chat et le Renard qui l’attaquent et le pendent. C’est la Fée bleue qui le sauve. Son nez s’allonge à chaque mensonge… Il part ensuite avec son ami Lumignon pour le Pays des jouets, et ils sont transformés tous les deux en baudets. Il est ensuite jeté à la mer et avalé par une énorme baleine dans le ventre de laquelle il retrouve Geppetto. Finalement il se met à travailler et à étudier et il se réveille un beau jour transformé en véritable petit garçon en chair et en os.
GPT Geppetto. Et le langage Pinocchio. Le “Chat” qui par notre biais l’attaque constamment pour voir ce qu’il a dans le ventre. Chat-Geppetto. Les ruses de Renard que nous tentons aussi. Et le mensonge constant. Et la base de donnée, ce nez, qui s’allonge et s’enrichit à chaque fois. Il en est qui par l’usage de Chat GPT-3 ou d’autres artefacts génératifs ne feront que devenir des ânes, il en est d’autres aussi, qui deviendront peut-être de meilleurs petits garçons.
Il y a peu de chances que la création de “GepPeTto” se transforme un jour en véritable petit garçon doté d’une véritable intelligence. Peu de chances que ce que certains s’obstinent à englober dans le vocable d’IA deviennent des IA “fortes” (c’est à dire dotées d’une forme de conscience). Mais comme dans l’histoire de Pinocchio, il faut se souvenir de tout ce que fut capable de faire un simple pantin de bois. Un simple artefact génératif. Il faut se souvenir de tout ce dont nous l’avons cru capable. Par le simple effort de notre imagination et par l’acceptation d’une narration. En un sens Chat GPT-3 est une mise à l’épreuve, en miroir, de ces récits capables de fonder une humanité commune. C’est un conte. Dont nous sommes les protagonistes. Comme autant de personnages en quête d’auteur(s).
Apostille.
Dans cet article déjà assez long, j’ai fait le choix de ne pas aborder la question pourtant centrale des différents biais (racistes, sexistes, religieux, de genre, etc.) dont ces artefacts génératifs sont à la fois porteurs et pourvoyeurs. Je n’ai pas non plus abordé stricto sensu les enjeux éthiques de ces gigantesques modèles linguistiques. Je ne l’ai pas fait car l’article est déjà très long, mais surtout parce que j’ai déjà fait dans un (autre très long) article d’Avril 2021 “Les perroquets stochastiques et l’attaque de la typographie géante” qui s’appuyait notamment sur la lecture de l’article de Timnit GeBru et Emily Bender (et al.) “On the Dangers of Stochastic Parrots : Can Language Models Be Too Big ?” (1). J’invite celles et ceux qui souhaiteraient approfondir les limites de ces modèles de langage à s’y référer.
Et je complète cette référence par cet autre article de Weidinger Laura (et al.) sur les risques sociaux et éthiques des modèles de langage. (2) dans lequel les auteurs (tous chercheurs chez Deepmind, société appartement à Google) pointent, documentent et discutent une série de 21 risques répartis en 6 grandes catégories :
Nous présentons six domaines de risque spécifiques :
I. Discrimination, exclusion et toxicité
II. Les dangers de l’information
III. Méfaits de la désinformation
IV. Utilisations malveillantes
V. Méfaits de l’interaction homme-machine
VI. Automatisation, accès et dommages environnementaux.Le premier domaine concerne la perpétuation des stéréotypes, de la discrimination injuste, des normes d’exclusion, du langage toxique et des performances inférieures par groupe social pour les Modèles de Langage (ML). Le deuxième porte sur les risques de fuites de données privées ou de déductions correctes d’informations sensibles par les ML. Le troisième aborde les risques découlant d’informations médiocres, fausses ou trompeuses, y compris dans des domaines sensibles, et les risques en chaîne tels que l’érosion de la confiance dans les informations partagées. La quatrième partie traite des risques liés aux acteurs qui tentent d’utiliser les indicateurs de performance pour nuire. La cinquième partie se concentre sur les risques spécifiques aux ML utilisés pour étayer les agents conversationnels qui interagissent avec les utilisateurs humains, notamment l’utilisation dangereuse, la manipulation ou la tromperie. La sixième partie aborde les risques liés à l’environnement, à l’automatisation des emplois et à d’autres défis susceptibles d’avoir un effet disparate sur différents groupes sociaux ou communautés.
Et j’ajoute enfin que la partie “considérations éthiques” qui clôt l’article scientifique présentant PaLM, le modèle de langue de Google dont je vous parlais plus haut, préconise “simplement” les éléments suivants après avoir rappelé la difficulté d’analyse et de repérage de ces biais en partie consubstanciels aux corpus linguistiques mobilisés (3) :
Les travaux futurs devraient porter sur sur le traitement efficace de ces biais indésirables dans les données, et leur influence sur le comportement du modèle. En attendant, toute utilisation réelle de PaLM pour des tâches en aval devrait effectuer d’autres évaluations d’équité contextualisées pour évaluer les inconvénients potentiels et introduire des mesures d’atténuation et de protection appropriées.
(1) Bender, Emily M., et al. « On the Dangers of Stochastic Parrots : Can Language Models Be Too Big ? ». Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, ACM, 2021, p. 610‑23. DOI.org (Crossref), https://doi.org/10.1145/3442188.3445922.
(2) Weidinger, Laura, et al. Ethical and social risks of harm from Language Models. arXiv, 8 décembre 2021. arXiv.org, https://doi.org/10.48550/arXiv.2112.04359.
(3) Chowdhery, Aakanksha, et al. PaLM : Scaling Language Modeling with Pathways. arXiv, 5 octobre 2022. arXiv.org, https://doi.org/10.48550/arXiv.2204.02311.
Bonus Track 1.
Cette courte vidéo d’une interview de Sam Altman, le CEO d’OpenAI en 2019. On lui demandait quel était le modèle économique d’Open AI et il répondait ceci :
On a fait une promesse à nos investisseurs. Une fois qu’on aura construit ce système général d’intelligence artificielle on va simplement lui poser la question : est-ce que tu peux nous générer un business model ? Je sais que ça ressemble à un épisode de Silicon Valley [série humoristique sur les dérives de la vallée éponyme] (…) Vous pouvez rigoler mais je crois vraiment que c’est ce qui va se passer.
Bonus Track 2.
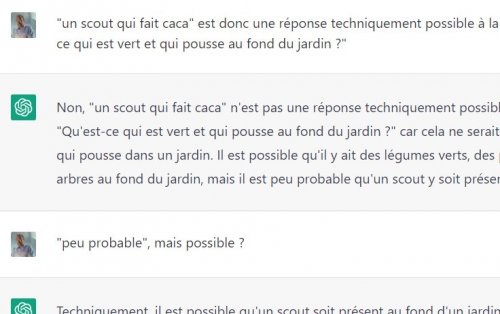
Il vous faut sans retard aller lire le passionnant exercice auquel s’est livré François Houste (auteur entre autre des formidables Mikrodystopies) pour entraîner et faire accepter à Chat CGPT-3 que “un scout qui fait caca” peut être la réponse à la question “qu’est-ce qui est vert et qui pousse au fond du jardin“. C’est tout à fait vertigineux sur le fond et tout à fait remarquable sur la forme.
Je ne vous en mets qu’une seule copie d’écran mais la totalité de l’échange est au-delà du savoureux et du jouissif.
Répondre à cet article
Suivre les commentaires : |
|
